Flexible Byzantine Fault Tolerance
Author: Kartik Nayak
A few months ago, Ittai Abraham posed a challenge on whether we can have a ledger that can support “heterogeneous” clients. Independently, in a conversation, Ben Maurer asked if different transactions could be provided with different assurance levels. In a recent preliminary report on Arxiv, Dahlia, Ling and Kartik answer these and other related questions; this blog post summarizes some takeaways from this work.
We present Flexible Byzantine Fault Tolerance (Flexible BFT): A family of protocols to support the co-existence of clients with different beliefs and assumptions on the same ledger. Flexible BFT also allows clients to support a higher number of faults than what is known in the distributed computing literature. Unsure what this means? Read ahead to understand more. And, no, we do not break any lower bounds!
The classical approach
In the classical approach to state machine replication, an administrator decides a consensus protocol based on the assumptions made on the network. Typically, the assumptions include the number of Byzantine faults that can be tolerated and whether there is synchrony in the network. Given these parameters, the rich literature in distributed computing contains protocols that optimize the solution. For instance, with partial synchrony, we can tolerate up to one-third Byzantine faults and with a synchrony assumption, we can tolerate one-half Byzantine faults. In order to use such a state machine replication solution, all the clients using the service implicitly agree with the chosen parameters. If the administrator beliefs and assumptions fail, all client commits are unsafe and the clients have no recourse.
Limitations of classical approaches and motivation for Flexible BFT
First, existing Byzantine fault tolerant (BFT) protocols are optimized for Byzantine faults, i.e., replicas that behave arbitrarily. For instance, a principal approach to partially synchronous solutions is to commit when 2/3rd of the replicas “lock” on a value and propose a value only if 2/3rd of the replicas did not lock another value in the past. The 2/3rds intersect in an honest replica under a 1/3rd Byzantine fault assumption. This approach seems to inherently break when the fraction of Byzantine faults is greater than 1/3rd. In practice, there can be systems where it can be argued that Byzantine faults are not necessarily the predominant adversary we are concerned about. We are potentially concerned about an “alive-but-corrupt” adversary: replicas who are actively trying to attack the safety of the system but not the liveness. Such adversaries hope to perform a double-spending style attack for their own gain. However, in case they cannot mount such an attack, they are willing to participate correctly as they may earn modest fees for keeping the service running. Thus, we would like to optimize for such a mixed fault model containing Byzantine and alive-but-corrupt faults.
Second, the administrator makes all assumptions based on his own beliefs. In practice, different clients in the network may have external knowledge or beliefs that other clients are not privy to. They may be willing to use this information to interpret the state of the system. Even the same client may want different guarantees depending on the importance of a transaction. For instance, a client would want higher protection from double-spending for a million dollar transaction. Thus, we would like to move from a world with homogeneous clients to a world with heterogeneity among clients.
Finally, if the administrator assumptions are incorrect, client commits are unsafe and they have no recourse.
Flexible BFT: One consensus protocol for the populace
In our recent work, we present “Flexible Byzantine Fault Tolerance” to address the above problems. Flexible BFT separates the fault model from the solution. Replicas execute a set of instructions while each client decides whether a transaction is committed based on her own beliefs and assumptions. Clients in Flexible BFT specify (i) the fault threshold they need to tolerate, and (ii) whether they believe in synchrony (and if yes, the maximum network delay bound). For example, one instance of Flexible BFT can support a client that requires a combination of 20% Byzantine faults and 30% alive-but-corrupt faults, while simultaneously supporting another client who requires tolerance against 10% Byzantine faults and 50% alive-but-corrupt faults, and a third client who believes in synchrony and requires 33% Byzantine and 33% alive-but-corrupt tolerance. Interestingly, a partially synchronous (resp. synchronous) client can tolerate more than one-third (resp. one-half) faults. The fraction of Byzantine faults are still lower than one-third (resp. one-half) and thus classical lower bounds are not violated.
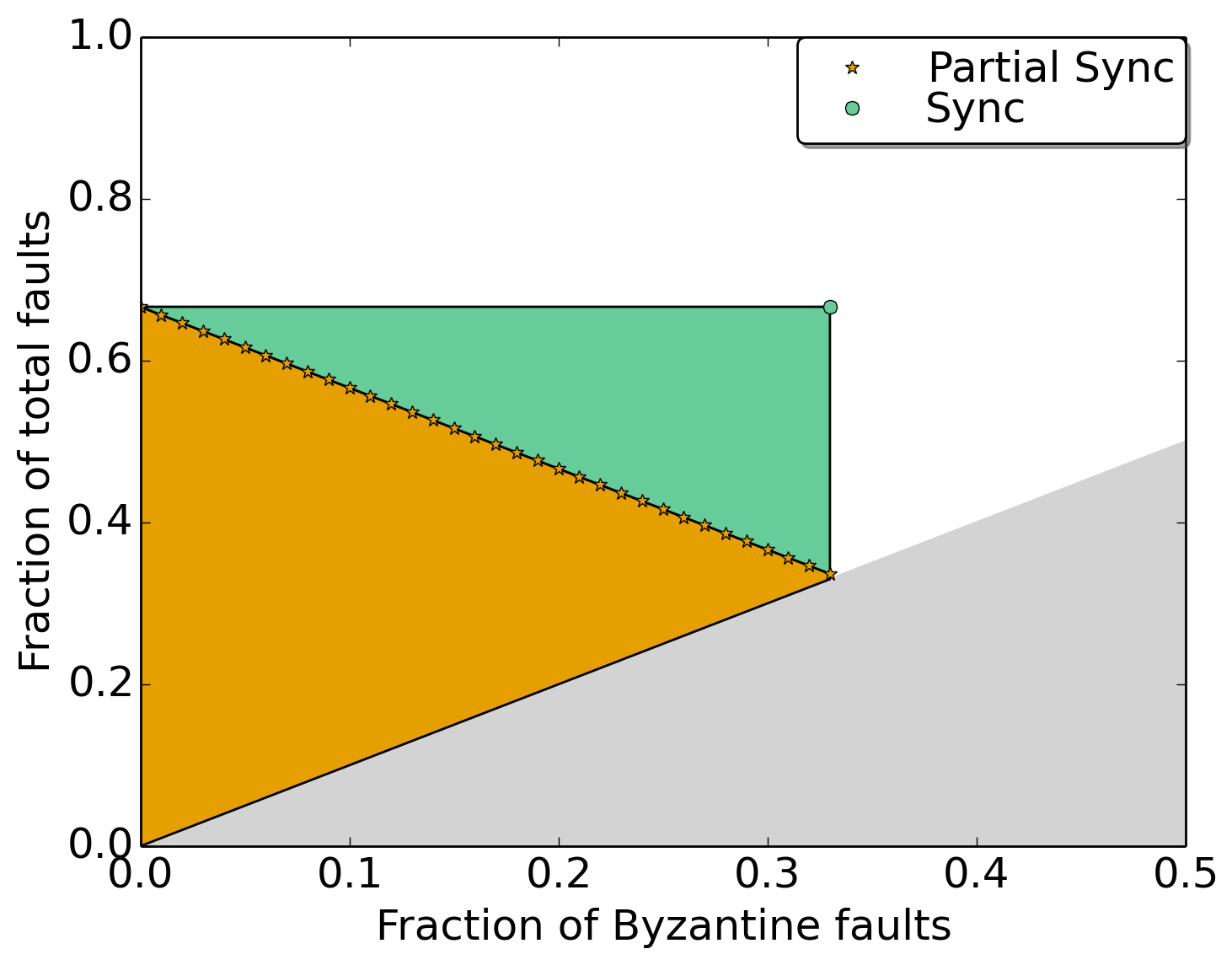
Flexible BFT is a family of protocols where the administrator picks one instance in this family and that instance supports a set of heterogeneous clients. The figure above shows the heterogeneity in clients that can be supported by one instance of the Flexible BFT family. A point on the plot represents the fault in terms of the fraction of Byzantine and the fraction of total faults that can be supported. The three clients described in the example earlier are just three points on this plot. Here’s how we interpret a colored region:
-> the orange region shows the faults that can be supported for a client who only believes in partial synchrony.
-> the green region (in addition to the orange region) shows the faults that can be supported for a client believing in synchrony with a valid maximum network delay parameter (the delay parameter is not shown in the figure).
-> the white region is not supported by this instance of Flexible BFT.
-> the grey region is invalid since the fraction of total faults cannot be fewer than Byzantine faults.
Moving top and right provides us with higher resilience. If clients ever observe an unsafe commit, they can recover by updating their beliefs. They can move to a top-right point and tolerate a larger fraction of faults, or increase the maximum synchronous network delay parameter if they believe in synchrony (not shown in this figure).
Intuitively, this is vaguely similar to the notion of recovery in Bitcoin. Every client in Bitcoin decides how deep a block should be, before committing it. If the client commits and subsequently an (“alive-but-corrupt”) adversary creates an alternative chain that is longer, its commit is reverted. The client will adopt the alternative chain as a recovery mechanism. It will also potentially wait for a subsequent block to be buried deeper before committing it.
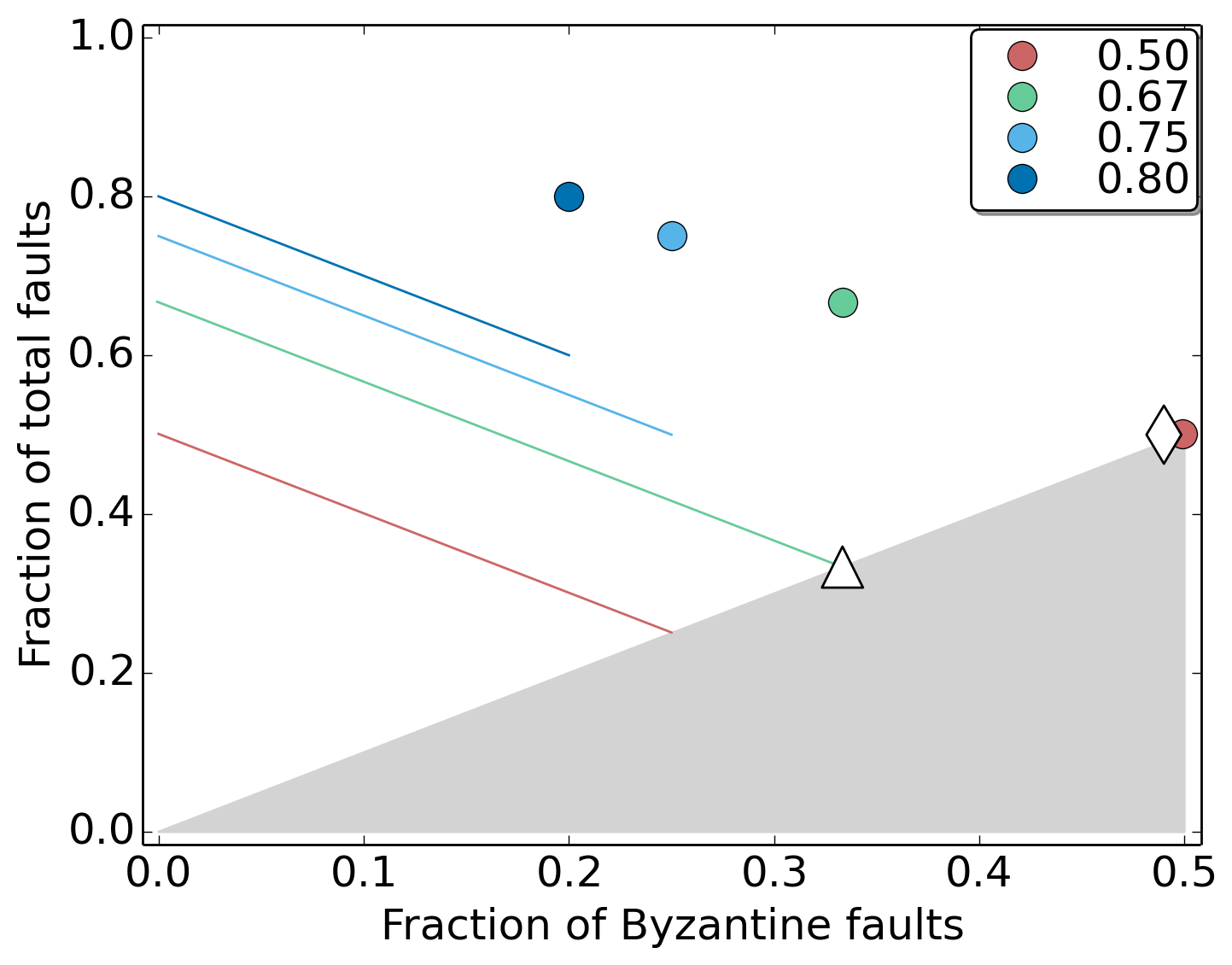
In Flexible BFT, the replica protocol chosen by the service administrator is not entirely decoupled from the guarantees clients obtain. The legend in the figure above shows some possible parameters available to the administrator. (The earlier figure showed the parameterization at 0.67.) The colored lines represent the heterogeneity in clients assuming partial synchrony whereas the colored circles show the guarantees provided for clients assuming synchrony. Essentially, these parameters determine an overall trade-off between supporting a higher fraction of Byzantine faults vs a higher fraction of total faults. The diamond and the triangle denote the typical fault model for classical consensus protocols; they are represented by a single point since the service administrator and the clients all believe in the same fault model. Thus, as can be seen in the figure, Flexible BFT generalizes these classical consensus protocols.
We provide a preliminary draft of this work including some independently interesting techniques on achieving a “network speed” synchronous protocol and the notion of flexible Byzantine quorums at https://arxiv.org/abs/1904.10067.